USENIX 2019 - 2 paper about Antifuzz
==本文不讨论Antifuzz技术的伦理==
==不要抱着”用这破技术不如积极响应漏洞报告修复漏洞来的有意义”这种杠精思想看==
Abstract
| Fuzzification | AntiFuzz | |
|---|---|---|
| Threat Model | attackers 使用==state-of-the-art== fuzzing技术 attackers使用==off-the-shelf==的binary分析技术对 protected binary中的FUZZIFICATION进行分析与disarm |
与Fuzzification类似 |
| Motivations | antifuzz, 不希望binary被外界的==malicious attacker==使用fuzzing技术进行漏洞挖掘。 将binary分为 original binary和protected binary(using Fuzzification),对外公开的只有protected binary,而original binary只有developer和trusted parties能够获取。similar in concept to using obfuscation techniques to cripple reverse engineering |
antifuzz, 没有太多想法,单纯的是想做一个针对fuzzing techniques的阻碍技术current obfuscation techniques are aimed at increasing the cost of human understanding and do little to slow down fuzzing. |
| implementations | SpeedBump: Amplifying Delay in Fuzzing BranchTrap: Blocking Coverage Feedback AntiHybrid: Thwarting Hybrid Fuzzers |
Attacking Coverage-guidance Preventing Crash Detection Delaying Execution Overloading Symbolic Execution Engines |
| usages | LLVM pass+Python Script | 需要靠developer手工在源代码里调用AntiFuzz给的函数,Python Script |
Fuzzification: Anti-Fuzzing Techniques
Specifically, attackers may still be able to find bugs from the binary protected by FUZZIFICATION, but with significantly more effort (e.g., CPU, memory, and time).
Introduction
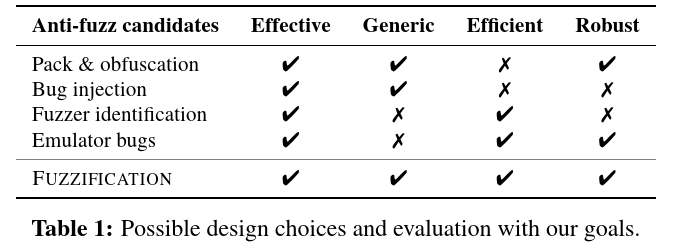
goals
- Effective: It should effectively reduce the number of bugs found in the protected binary, compared to that found in the original binary.
- Generic: It tackles the fundamental principles of fuzzing and is generally applicable to most fuzzers.
- Efficient: It introduces minor overhead to the normal program execution.
- Robust: It is resistant to the adversarial analysis trying to remove it from the protected binary.
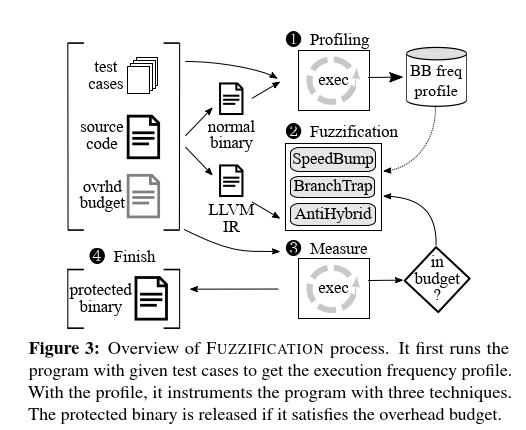
Techniques & Implementations
SpeedBump
The SpeedBump technique aims to slow program execution during fuzzing.
It injects delays to cold paths, which normal executions rarely reach but that fuzzed executions frequently visit.
SpeedBump在==cold path==(fuzzing执行时会频繁触及但是正常执行时几乎不会涉及的path)中注入细粒度的delay primitives
fuzzed execution会很频繁地进入如error-handling(e.g. , wrong MAGIC bytes)的路径,而normal execution则很少访问。将此类path命名为==cold path==
identify cold paths
SpeedBump检测目标程序以在执行过程中计算访问的基本块,并生成用于分析的二进制文件- 使用
user-provided test cases,运行此二进制文件并收集每个输入所访问的基本块 - 分析收集到的信息以识别很少由有效输入执行或从未执行的基本块
此处相当于使用fuzzing进行分析
小缺陷:这个操作并不能找到100%的路径
Our profiling does not require the given test cases to cover 100% of all legitimate paths, but just to trigger the commonly used functionalities.
也就是说这一步是搜索了common paths或者说是面向fuzzing的common paths,毕竟连fuzzer都找不到的路径,对它加料的意义不大
SpeedBump给出的5个参数:
MAX_OVERHEADDELAY_LENGTHINCLUDE_INCORRECT-选择是否在error-handling基本块中注入delays,默认为enabled。INCLUDE_NON_EXECandNON_EXEC_RATIO-指明是否无论有多少从未执行过的基本块均一律注入delays,当testcases并不是足够大时很有用
关于第三点的INCLUDE_INCORRECT,目的是为了绕过VUzzer和T-Fuzz等fuzzers对error-handling basic blocks的识别。做法是用类似的技术先把error-handling basic blocks识别出来
Analysis-resistant Delay Primitives
we design robust primitives that involve arithmetic operations and are connected with the original code base. Our primitives are based on ==CSmith(Modified)==
具体修改内容:
We modified CSmith to generate code that has data dependencies and code dependencies to the original code.

目的是保证delay primitives的安全性。
现代的二进制分析技术中有一项技术为dead-code elimination/死代码消除,如果不对这些注入的”垃圾指令”进行处理使其与原代码之间生成dependency,那么这些delya primitives会被作为dead code清除掉。
Safety of delay primitives
FUZZIFICATION将对delay primitives的安全性检查分类两部分:
- CSmith缺省的安全检查
FUZZIFICATION设计的检测机制。FUZZIFICATION also has a separate step to help detect bad side effects (e.g., crashes) in delay primitives.
BranchTrap
The BranchTrap technique inserts a large number of input-sensitive jumps into the program so that any input drift will significantly change the execution path.
BranchTrap包含了两个方法
Method 1
BranchTrap的第一部分通过伪造大量input-sensitive branchs来诱导==coverage-base fuzzers==浪费计算资源在这些==bug-free branchs==上
four design aspects
BranchTrap应该制造足够数量的fake path以影响fuzzing policy。并且fake paths应提供不同的受输入影响的coverage,使得fuzzer能不断地陷入Traps- 注入的新路径给
Normal Executions带来的开销最小化 - 路径的确定性,the same input should go through the same path
BranchTrap无法轻易被识别或删除
简单的实现方式:使用一个跳转表,根据不同的输入会跳转到不同的目标。容易被检测出来
BranchTrap的实现方式:使用代码重用技术设计和实现,其概念类似于Return-Oriented Programming(ROP)
steps:
- 从程序的汇编中收集函数的结尾(
function epilogues)(在程序编译时生成) - 将具有相同指令序列的函数结尾分组到一个跳转表中
- 重写汇编使得每个函数根据特定索引从跳转表跳转到与原结尾等价的gadget上并正确返回(不影响实际的控制流)
工作流程:
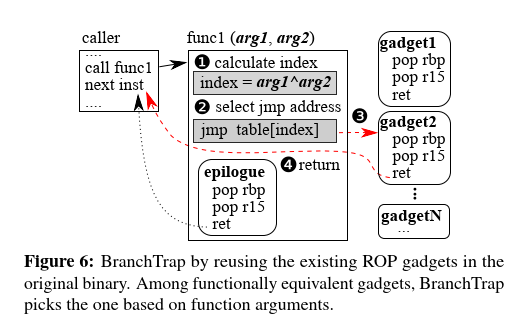
- 计算所有参数的异或值
XORed value - 通过该值作为索引,访问跳转表中选择跳转地址(避免out-of-bound,异或值作模运算)
- 确定跳转地址后,控制流将转到gadget
- 最后,执行会返回到原返回地址
Method 2
BranchTrap的第二种方法是使模糊状态饱和(to saturate the fuzzing state)
与第一种方法引起fuzzer专注于毫无结果的输入不同,我们这里的目标是防止fuzzer找到真正有趣的输入
为此,BranchTrap在程序中插入了大量分支,并利用每个fuzzer的代码覆盖率表示机制来掩盖新发现。
Method 2能够向极少被访问的基本块中注入大量(例如1万到10万)确定性分支。一旦fuzzer到达这些基本块,其覆盖范围表将迅速填满。
AntiHybrid
The AntiHybrid technique aims to thwart hybrid fuzzing approaches that incorporate traditional fuzzing methods with dynamic taint analysis and symbolic execution.
AntiHybrid将显式数据流转换为隐式数据流,以防止通过污点分析进行数据流跟踪,并插入大量spurious symbols以在符号执行期间触发路径爆炸
Hybrid的弱点:
- 无论symbolic execution还是taint analysis都会消耗大量CPU和内存资源,导致其只能局限于分析简单的程序
- symbolic execution受限于路径爆炸问题
- DTA不擅长追踪隐式数据依赖性(implicit data dependency),比如
covert channels, control channels, timing-based channels
Introducing implicit data-flow dependencies
FUZZIFICATION将程序中的显式数据流转换为隐式数据流以防止污点分析。
FUZZIFICATION首先确定分支条件和interesting information sinks(比如strcmp),然后根据变量类型注入数据流转换代码。

隐式数据流阻碍了跟踪直接数据传播的数据流分析。但是,它无法通过差异分析来防止数据依赖性推断。例如,最近的著作RedQueen [2]通过模式匹配推断输入条件和分支条件之间的潜在关系,从而可以绕过隐式数据流转换。但是,RedQueen要求在输入中显式显示分支条件值,可以通过简单的数据修改(例如,将相同的常量值添加到比较的两个操作数中)轻易地弄虚作假。
Exploding path constraints
以路径爆炸为目的,FUZZIFICATION将每个比较指令替换成对原始值的hash的比较
We adopt the hash function because symbolic execution cannot easily determine the original operand with the given hash value.
FUZZIFICATION利用轻量级的循环冗余校验(CRC)循环迭代来转换分支条件以避免过度的性能开销。==尽管从理论上讲,CRC在阻止符号执行方面不如散列函数那么强,但它也带来了显着的阻碍效果。==
For example, QSym, a state-ofthe-art fast symbolic execution engine, is armed with many heuristics to scale on real-world applications. When QSym first tries to solve the complicated constraint that we injected, it will fail due to the timeout or path explosion.
Once injected codes are run by the fuzzer multiple times, QSym identifies the repetitive basic blocks (i.e., injected hash function) and performs basic block pruning, which decides not to generate a further constraint from it to assign resources into a new constraint. After that, QSym will not explore the condition with the injected hash function; thus, the code in the branch can be explored rarely.
Evaluation
implementation
FUZZIFICATION framework is implemented in a total of 6,559 lines of Python code and 758 lines of C++ code.
具体三项模块的实现有一些复杂
- SpeedBump: 作为一个
LLVM pass实现,在编译时将delay primitives注入代码块 - BranchTrap: 对汇编代码进行分析并直接修改
- AntiHybrid: 使用
LLVM pass引入路径爆炸,使用python脚本自动注入隐式数据流
Currently, our system supports all three FUZZIFICATION techniques on 64bit applications, and is able to protect 32bit applications except for the ROP-based BranchTrap.
由于BranchTrap的method 1的思想是基于ROP的,而ROP在32bit和64bit的应用的策略是有较大差异的,因此让method 1支持32bit应当需要一定的修改
关于LLVM pass: http://llvm.org/docs/WritingAnLLVMPass.html#introduction-what-is-a-pass
The LLVM Pass Framework is an important part of the LLVM system, because LLVM passes are where most of the interesting parts of the compiler exist. Passes perform the transformations and optimizations that make up the compiler, they build the analysis results that are used by these transformations, and they are, above all, a structuring technique for compiler code.
Experimental setup
针对可在二进制文件上运行的四个最先进的fuzzers评估FUZZIFICATION:
- AFL in QEMU mode
- HonggFuzz in Intel-PT mode
- VUzzer 32
- QSym with AFL-QEMU
We also tried to use VUzzer64 to fuzz different programs, but it did not find any crashes even for any original binary after three-day fuzzing. Since VUzzer64 is still experimental, we will try the stable version in the future.
评估所用设备:
- Intel Xeon CPU E78890 v4@2.20GHz, 192 processors and 504 GB of RAM
- Intel Xeon CPU E7-4820@2.00GHz, 32 processors and 128 GB of RAM
为了获得可重现的结果,即试图消除fuzzers的不确定因素:
禁用了实验机的地址空间布局随机化(
address space layout randomization)并强制AFL采用确定性模式(deterministic)。但是必须在HonggFuzz和VUzzer中保留随机性,因为它们不支持deterministic fuzzing。对FUZZIFICATION中的基本块配置使用了相同的测试用例集,并为不同的Fuzzer提供了相同的种子输入。
- 对每个目标应用程序进行代码检测和二进制重写时,使用相同的FUZZIFICATION技术和配置。
- 我们预先生成了FUZZIFICATION原语(例如10ms至300ms的SpeedBump代码和具有确定性分支的BranchTrap代码),并将原语用于所有保护(请注意,开发人员应为实际的发布二进制文件使用不同的原语,以避免代码模式匹配分析)
Target applications
- LAVA-M 数据集
- 9个实际应用
- Google fuzzer test-suite
- four programs from the binutils
- the PDF reader MuPDF
作者团队对这些二进制文件执行了两组实验:
- 用三个fuzzers(除了VUzzer)fuzz 9个现实程序,以测量FUZZIFICATION对查找代码路径的影响。
- 具体而言,我们编译具有五个不同设置的八个真实程序(MuPDF除外);原始程序(无保护),SpeedBump,BranchTrap,AntiHybrid和三种技术的组合(全面保护)
- 为了简单起见,我们用两个设置编译MuPDF:无保护和完全保护
- 我们使用三个fuzzers对四个binutils程序进行fuzz,并使用所有四个fuzzers来对LAVA-M程序进行fuzz,以评估FUZZIFICATION对
unique bugs finding的影响。
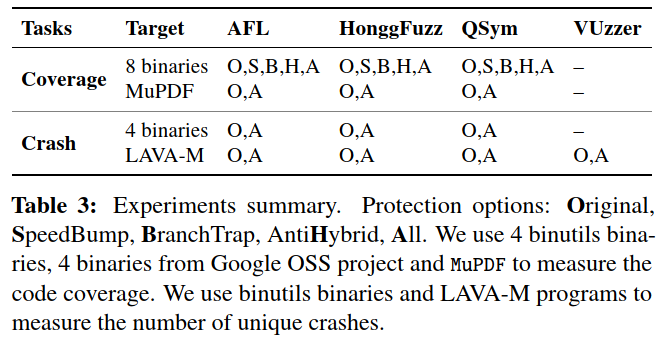
Table 4显示了我们的编译中使用的每种技术的配置。
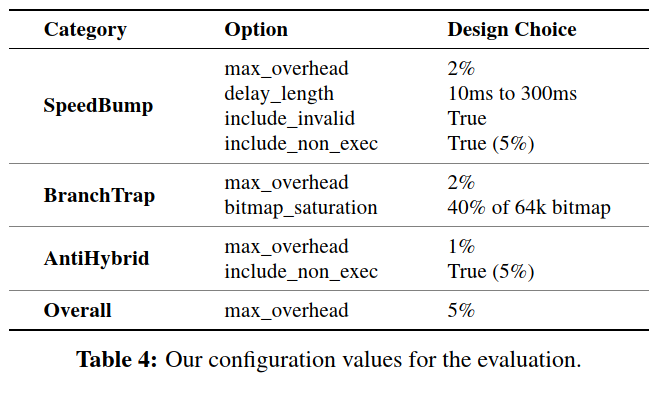
Evaluation metric
code coverage in terms of discovered real paths
- 实际路径是原始程序中显示的执行路径,不包括BranchTrap引入的伪造路径。我们进一步排除了由种子输入触发的真实路径,因此我们可以专注于fuzzer发现的路径。
unique crashes
- 唯一崩溃被测量为可以使程序以不同的真实路径崩溃的输入。我们过滤掉了AFL中定义的重复崩溃。
Reducing Code Coverage
Impact On Normal Fuzzers
In summary, with all three techniques, FUZZIFICATION can reduce discovered real paths by 76% to AFL, and by 67% to HonggFuzz, on average.
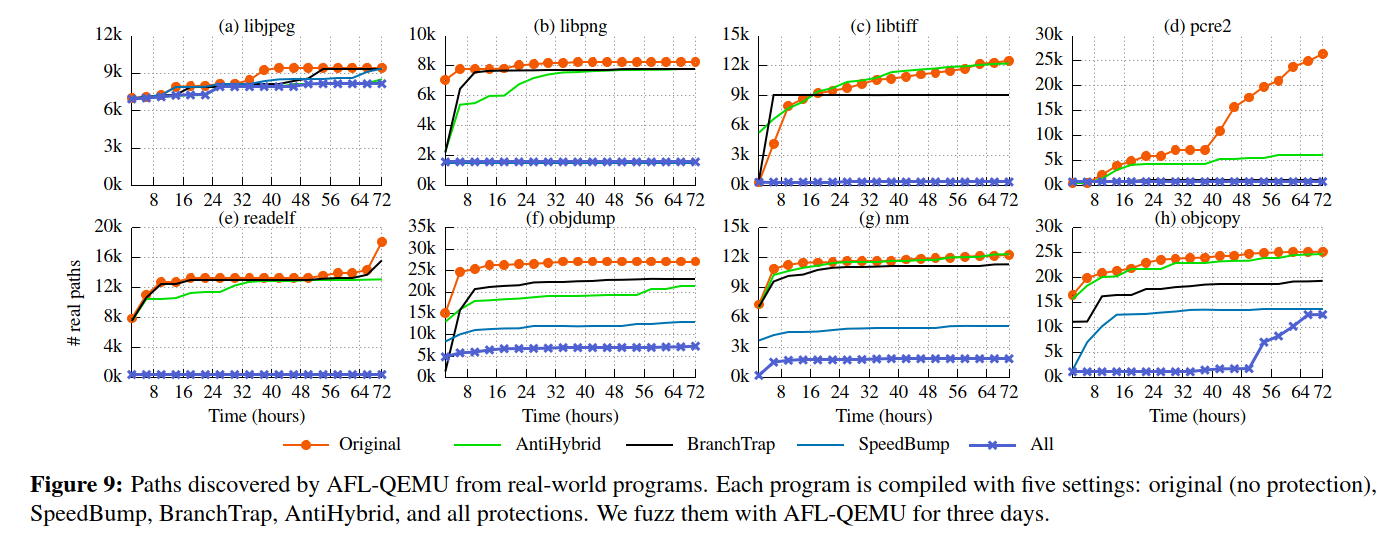
Table 5显示了每种技术对阻碍路径发现的影响。其中,SpeedBump可以最好地防御普通的fuzzers,其次是BranchTrap和AntiHybrid。
有趣的是,尽管开发了AntiHybrid来阻止混合方法,但它也有助于减少正常的fuzzers中发现的路径。我们认为这主要是由于执行fuzz的情况导致的。
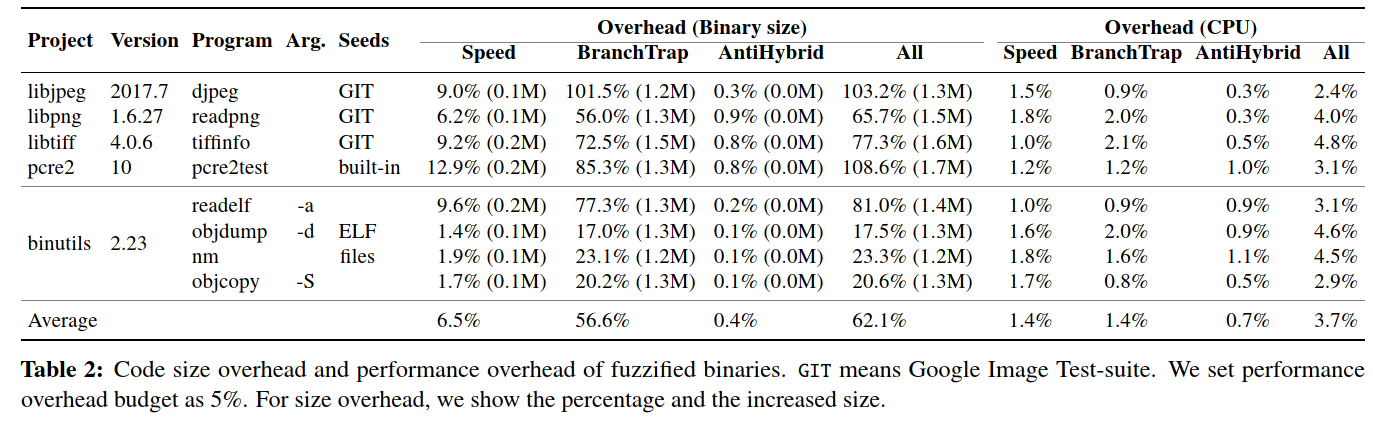
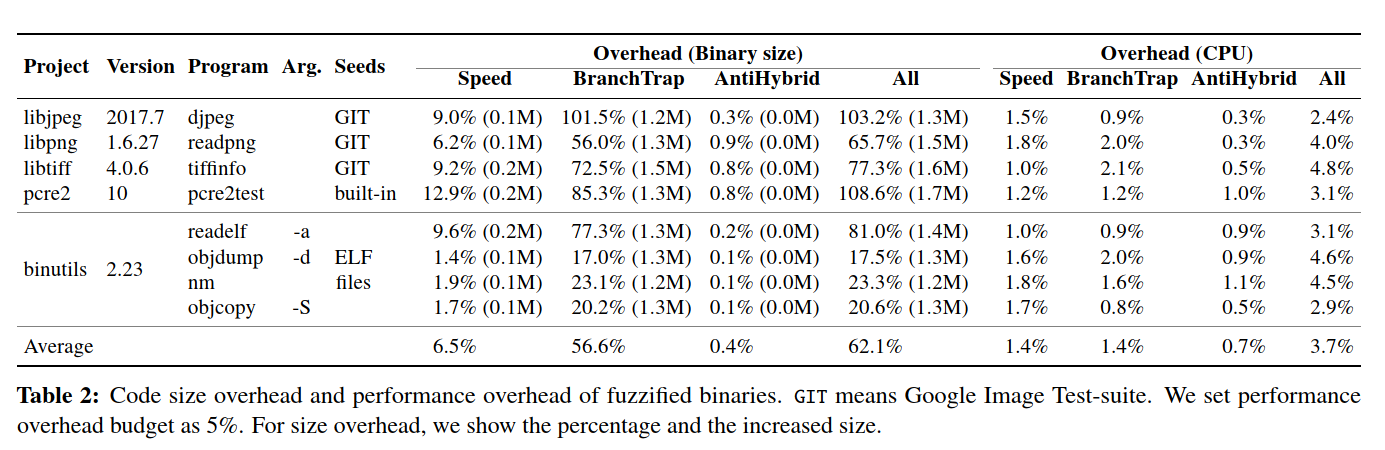
FUZZIFICATION满足用户指定的开销预算,但显示出相对较高的空间开销。
使用FUZZIFICATION的二进制文件平均比原始二进制文件大62.1%。
额外的代码主要来自BranchTrap技术
小型程序的size开销很高,而大型应用程序的size开销可以忽略不计。
Analysis on less effective results
FUZZIFUCATION对libjpeg的效果不好,分析之后,发现SpeedBump和BranchTrap无法有效地保护libjpeg。具体而言,这两种技术仅在用户指定的开销预算中注入了九个基本块(对于SpeedBump为2%,对于BranchTrap为2%),这少于所有基本块的0.1%。
Impact on Hybrid Fuzzers
针对QSym评估了FUZZIFICATION对代码覆盖率的影响。
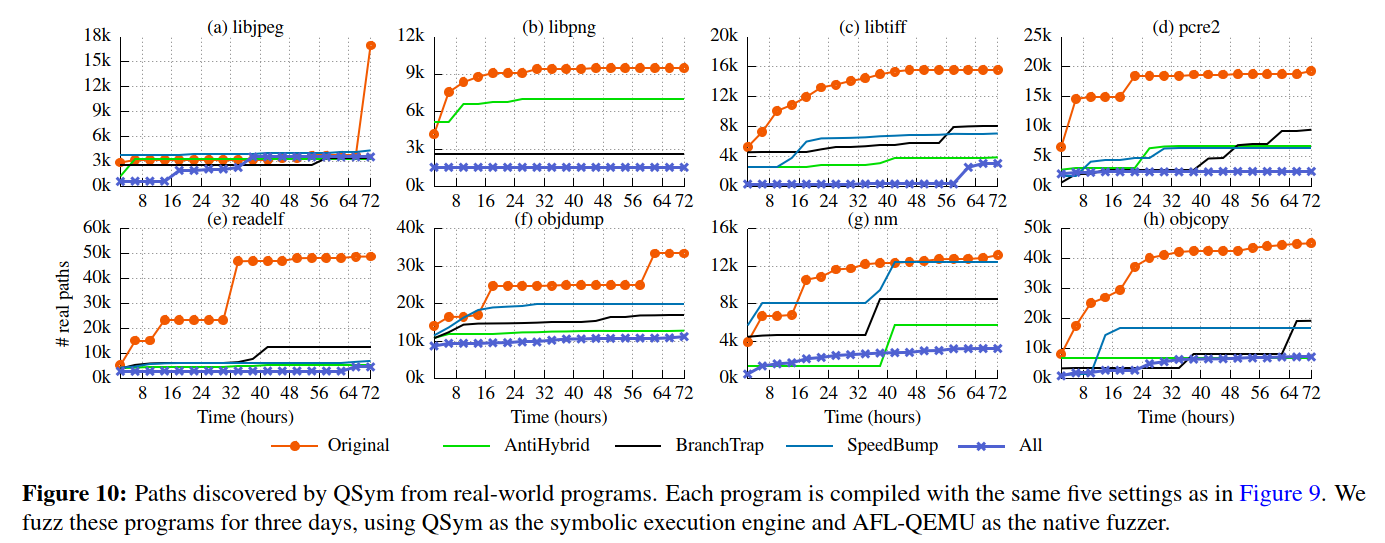
总体而言,同时使用这三种技术,FUZZIFICATION可以将QSym路径覆盖率降低80%,并且在所有测试程序中均显示出一致的高效性。减少率在66%(objdump)到90%(readelf)之间
6.2 Hindering Bug Finding
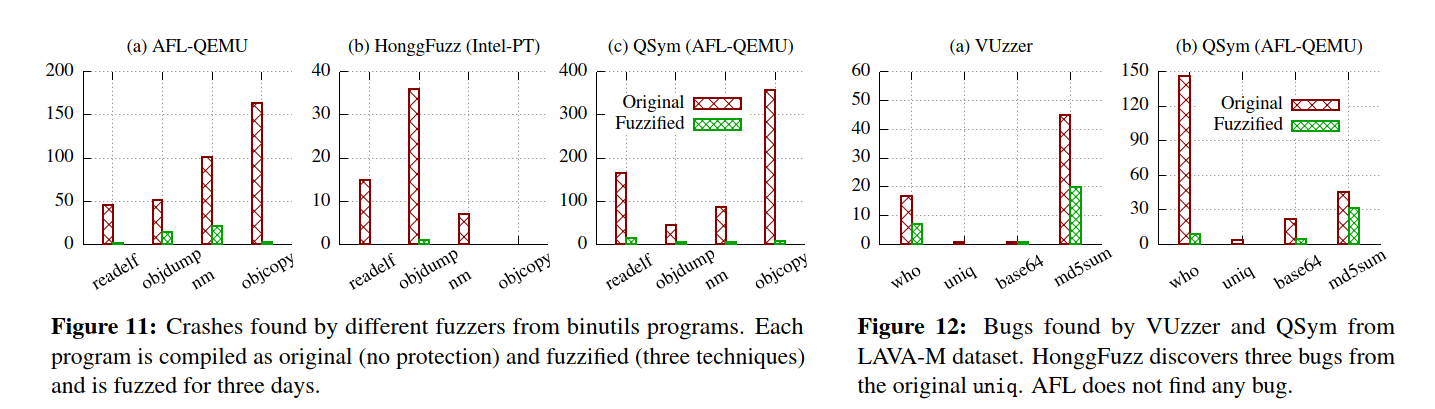
我们的评估首先用三个fuzzers(除了VUzzer之外)模糊测试四个binutils程序和LAVA-M应用程序。然后,我们用VUzzer对LAVA-M程序进行模糊测试,在其中将它们编译为32位版本,并排除了对32位程序尚未实现的基于ROP的BranchTrap的保护。
6.2.1 Impact on Real-World Applications
总体上,FUZZIFICATION将发现的崩溃数量减少了93%,特别是AFL减少了88%,HonggFuzz减少了98%,QSym减少了94%。
6.2.2 Impact on LAVA-M Dataset
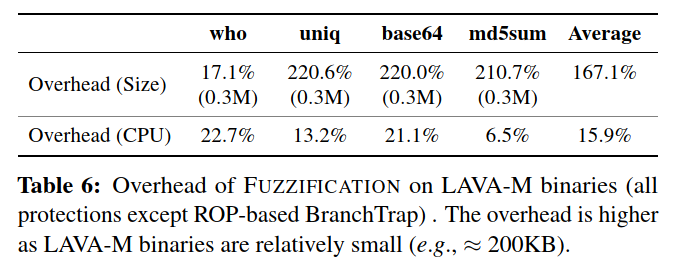
LAVA-M程序体积更小,操作更简单。如果我们对很少执行的二进制二进制代码的1%注入1ms的延迟,则该程序的速度将降低40倍以上。
要将FUZZIFICATION应用于LAVA-M数据集,我们需要更高的开销预算并应用更多细粒度的FUZZIFICATION。具体来说,我们使用了微小的
delay primitives(即10 µs至100 µs),将基本块检测的比例从1%调整为0.1%,减少了应用的AntiHybrid组件的数量,并注入了较小的deterministic branches以减少代码大小的开销。总体而言,模糊化可以减少VUzzer发现的错误的56%和QSym减少的发现的78%。
==请注意,原始二进制文件的模糊测试结果与原始论文[67,52]中报告的结果有所不同,原因有几个:VUzzer和QSym无法消除模糊过程中的不确定步骤; 我们以QEMU模式运行每个工具的AFL部分; LAVA-M数据集已更新,其中包含一些错误修复。==
6.3 Anti-fuzzing on Realistic Applications
为了了解FUZZIFICATION在大型实际应用中的实用性,我们选择了六个具有图形用户界面(GUI)并依赖于数十个库的程序。
三项技术针对此类程序的具体实现:
当应用SpeedBump技术时,由于缺少命令行界面(CLI)支持,我们不得不跳过基本块分析步骤
对于BranchTrap技术,我们选择将大量的假分支注入到入口点附近的基本块中。这样,程序执行将始终通过注入的组件,以便我们可以正确地测量运行时开销。
直接应用AntiHybrid技术。
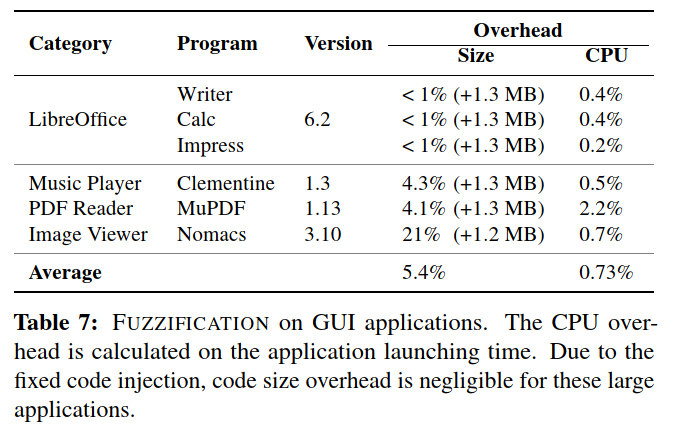
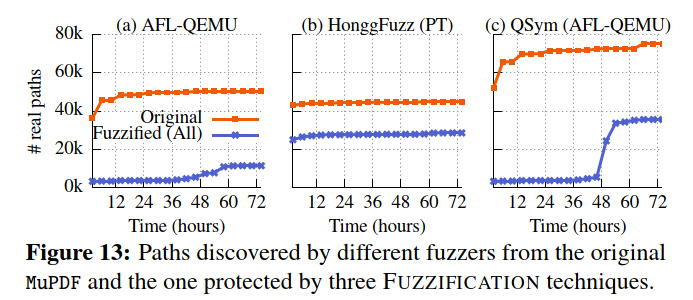
Anti-fuzzing on MuPDF
我们使用表4中所示的相同参数编译了二进制文件并执行了基本操作使用CLI界面进行性能分析
经过72小时的模糊测试后,没有任何fuzzers从MuPDF中发现任何错误。
对于实际路径指标,FUZZIFICATION平均将路径数减少了55%,特别是AFL减少了77%,HonggFuzz减少了36%,QSym减少了52%
6.4 Evaluating Best-effort Countermeasures
评估了FUZZIFICATION的鲁棒性。

paper中设想的攻击者的攻击方式包括模式匹配、控制流分析、数据流分析和人工分析
模式匹配:
AntiHybrid注入的代码,例如哈希算法和数据流重构代码,是可以被攻击者检测到的。
解决该问题的一种可能方法是使用现有的分集(diversity)技术来消除common pattern
而在SpeedBump和BranchTrap中找不到特定的模式
因为我们利用CSmith为每个FUZZIFICATION进程随机生成一个新的代码片段。
控制流分析
控制流分析可以用于消除死代码。
但是,由于所有注入的代码都与原始代码交叉引用,因此该技术无法删除我们的模糊化技术。
数据流分析
数据流分析能够识别数据依赖性
我们确认数据依赖关系始终通过全局变量,参数和注入函数的返回值存在
人工分析
我们考虑一个能够利用我们的技术知识进行手动分析以识别反模糊代码的对手。
由于FUZZIFICATION注入的代码是对原始功能的补充,因此我们得出结论,手动分析最终可以通过评估代码的实际功能来识别并消除我们的技术。但是,由于注入的代码在功能上与常规算术运算相似,并且对原始代码具有控制和数据依赖性,因此我们认为手动分析既耗时又容易出错
Discussion and Future Work
Complementing attack mitigation system
==The goal of anti-fuzzing is not to completely hide all vulnerabilities from adversaries. Instead, it introduces an expensive cost on the attackers’ side when they try to fuzz the program to find bugs, and thus developers are able to detect bugs first and fix them in a timely manner.==
==Therefore, we believe our antifuzzing technique is an important complement to the current attack mitigation ecosystem.==
现有的其他两种缓解措施:
- 避免程序错误(e.g.
使用类型安全的语言) - 阻止成功用漏洞(e.g.
控制流完整性检查)
Best-effort protection against adversarial analysis
防御方法只能提供尽力而为的保护。
首先,如果攻击者拥有几乎无限的资源,例如当他们发起APT(高级持续威胁)攻击时,没有防御机制可以在强大的对抗性分析中幸免。
其次,我们仅检查了现有技术,无法涵盖所有可能的分析。
知道我们的FUZZIFICATION技术细节的攻击者可能会提出一种特定的方法来有效地绕过保护。
Trade-off performance for security
FUZZIFICATION的保护非常灵活,我们为开发人员提供各种配置选项,以决定安全性和性能之间的最佳折衷,并且我们的工具将自动确定开销预算下的最大保护。
Delay primitive on different H/W environments
对延迟的测量是在开发者的机器上进行的,也就是这些注入的Delay primitives在更强大的硬件支持下无法达到预期的延迟效果。
另一方面,Delay primitives对于相对性能更弱的用户将造成更大的开销。
To handle this, we plan to develop an additional variation that can dynamically adjust the delay primitives at runtime.
Related Work
Fuzzing
略
Anti-Fuzzing techniques
Göransson等评估了两种简单直接的技术:
- 掩饰crash来防止被fuzzers发现crashes
- fuzzer检测,在被fuzzing时隐藏函数避免被测试
However, attackers can easily detect these methods and bypass them for effective fuzzing.
Hu等提出通过向程序注入可证明的不可利用的bug(称为”Chaff Bug”)来阻止攻击。
==Both chaff bugs and FUZZIFICATION techniques work on close-source programs.==
FUZZIFICATION的优势:
However, our methods, at most, introduce slow down to the execution, while improper chaff bugs lead to crashes, thus harming the usability.
Anti-analysis techniques
Sharif等设计了一个条件代码混淆,该条件代码混淆使用密码操作对条件分支进行加密。
Wang等提出了一种通过使用线性运算而不是加密函数来从符号执行中强化二进制代码的方法。
但是,他们都不认为性能开销是评估指标。
Conclusion
我们为开发人员提出了一种新的攻击缓解系统,称为FUZZIFICATION,以防止对抗性模糊测试。我们开发了三种防止模糊测试的方法:为延迟模糊执行而注入延迟;插入虚假分支以混淆覆盖范围反馈;转换数据流以防止污染分析,并利用复杂的约束削弱符号执行。我们设计了强大的反模糊测试原语,以阻止攻击者绕过FUZZIFICATION。我们的评估表明,对于真实世界的二进制文件,FUZZIFICATION可以将路径探索减少70.3%,将错误发现减少93.0%,对于LAVA-M数据集,可以将错误发现减少67.5%。
Questions
- rarely executed path 在一个程序中会是怎样的path
- FUZZIFICATION对注入的代码添加了control dependency 和 data dependency。但是这个dependency应该是与input无关或者关联度不大的。所以我能否通过一个advanced dead code elimination or input-guided dead code elimination将这些代码消除
- 针对
BranchTrap#1,我能否实现一个较为模糊的coverage-feedback,当执行遭遇到”乱跳”时选择性地忽略这些块,即将epilogue block不作为具有指导意义的覆盖度指标,而是将其上下文的blocks作为一个反馈 - 按照Fuzzification的设计,大部分的操作都是应用在所谓的
rarely executed paths上的,也就是说其他的frequently executed paths的overhead理论上是比较小的。那么是不是可以有一个设想,anti-antifuzz能否通过记录比较每次执行的时间来避开fuzzification设计的陷阱。————可能不行,这样很有可能会导致fuzzer只对常规路径进行探索,而导致fuzzer做无用功。 Hybrid环节的CRCloop,或者其他的hash()函数,能否通过一定的分析手段将其识别并还原成直接的比较函数。同理,BranchTrap#1是否也能还原
AntiFuzz: Impeding Fuzzing Audits of Binary Executables
Introduction
==否定了obfuscation==
even very high levels of obfuscation will typically result only in a meager slowdown of current fuzzing techniques.
==这一块,该paper跟Fuzzification有明显的分歧==
目标:生成轻量级的高效antifuzzing technique
assumptions
作者认为所有的fuzzer都至少满足一个以下的假设
- coverage会产生相对应的反馈
- crashes可以被检测到
- 每秒可以执行多次
- 使用符号执行可以解决约束
Contribution
- 对当前的模糊器所采用的技术进行了概述,并系统地分析了它们所做的基本假设
- 演示了通过对程序做极小的修改就能无效化fuzzing的各种优势。发现在不手动删除antifuzz techniques的情况下,fuzzing发现程序bug变得非常困难
- 在命名为
ANTIFUZZ的工具中实现了Antifuzz techniques,该工具在编译阶段添加antifuzz对策。对几种不同的程序进行评估,评估表明ANTIFUZZ的性能开销可以忽略不计
开源项目:https://github.com/RUB-SysSec/antifuzz
Technical Background
略,老生常谈的fuzzing编年史/发展史
从原始的随机测试到运用机器学习的输入生成应用到fuzzing中
列了很多文献,可以作为扩展阅读
这里从slide上撸点简单的东西下来
Blind Fuzzer
- Mutate input
- See if it crashes with given input
Coverage-guided Fuzzer
- Mutate input
- See if it crashes with given input
- … or if new coverage s found
- If so, add input to queue
- New Coverage => New Behavior
Hybrid Fuzzer
一般使用符号执行或者污点分析
一般是针对魔术值而应用Hybrid Techniques
The archetypal hybrid fuzzer is DRILLER, which uses concolic execution to search for inputs that produce new coverage.It tries to provide a comprehensive analysis of the program’s behaviour.
In contrast, QSYM identified this behavior as a weakness since the fuzzer can validate that the input proposed by the symbolic or concolic execution generates new coverage very cheaply.
Therefore, an unsound symbolic or concolic execution engine can produce a large number of false positive proposals, without reducing the overall performance of the fuzzer.
3 Analysis of Fuzzing Assumptions
两个基础的原始假设:
- crash detection 崩溃检测
- high execution throughput 高执行吞吐量
为了在现代模糊器中获得更好的性能,在过去的几年中,作者团队进行了进一步的假设:
- Coverage Yields Relevant Feedback Coverage-guided fuzzers.现代的
Coverage-guided fuzzer每次生成一个遍历新代码区域的输入时,都会假定该程序的行为与以前的输入不同。 - Crashes Can Be Detected Triggering security-relevant bugs will typically lead to a program crash.自1981年以来,几乎所有的随机测试工具都采用这种假设。
- Many Executions per Second To efficiently generate input files with great coverage, the number of executions per second needs to be as high as possible.大部分fuzzer的性能,很大程度上依赖于执行速度
先前假设中提到的所有模糊测试也属于此类。仅纯符号执行工具(例如KLEE)不属于此类。 - Constraints Are Solvable with Symbolic Execution Hybrid fuzzers or tools based on symbolic execution (such as DRILLER, KLEE, QSYM, and T-FUZZ) need to be able to represent the program’s behavior symbolically and solve the resulting formulas.因此,仅当被测程序的语义足够简单时,任何基于
symbolic/concolic execution的工具才能正常运行。
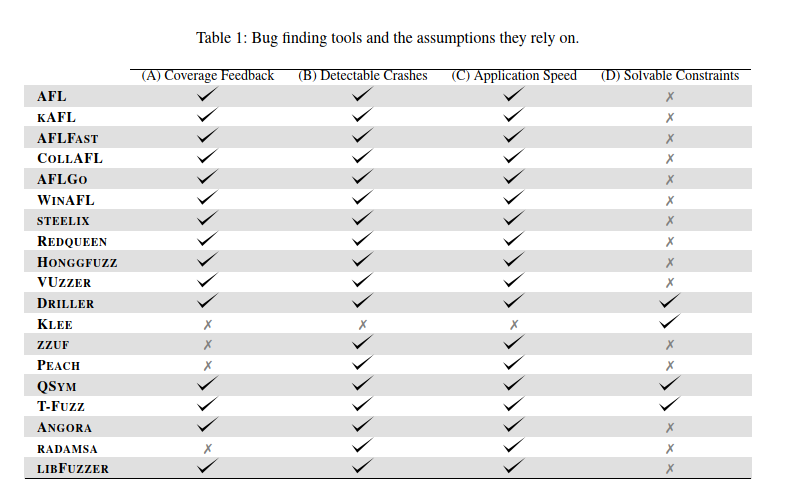
值得一提的是,该表中的各种工具均基于AFL,因此具有相同的假设。
4 Impeding Fuzzing Audits
Attacker Model:
假设攻击者只能访问最终受保护的二进制可执行文件,而不能访问原始源代码。
Commonly there is the notion that source-based fuzzers significantly outperform binary-only fuzzers.
目前存在着一种观念,认为基于源代码的fuzzer比仅二进制的fuzzers有明显的成本优势
但是,近来的模糊测试进展表明,这种优势正在下降。
另外,即使在仅二进制目标中,智能模糊技术也优于基于源的模糊
某些大型软件项目(例如某些PDF查看器和管理程序)不仅受到开发人员的良性测试,而且还受到白帽攻击者的良性测试。这种额外的关注是其安全模型中的重要因素。
同样,具有与独立研究人员进行有益交流的历史的项目应考虑不要使用ANTIFUZZ。取而代之,具有如此成功的社区集成历史的项目可以选择将不受保护的二进制文件释放给一组值得信赖的安全研究人员。
另一方面,绝大多数软件很少引起人们的关注。这些鲜为人知的软件仍被许多用户使用,它们可能会显著提高防止模糊测试的标准(例如工业控制器,如PLC或其他类型的专有软件)。
本文对攻击场景做出的假设:
- 攻击者可以使用任何最新的漏洞挖掘工具
- 攻击者不采用人工分析,尽管现实中目标程序可能会被人工分析,但是本文假定ANTIFUZZ与其他技术相结合,而这些技术在逆向工程期间会给人工分析人员带来巨大的成本。因此本文为区分不同的关注点(防御fuzzing和防御人工分析),明确将人工分析排除在攻击者模型外
4.1 Attacking Coverage-giudance
coverage-guided fuzzers的核心假设是new coverage indicates new behavior
为了破坏这一假设,ANTIFUZZ通过添加不相关的代码使其代码覆盖率的信息淹没实际信息,以此对抗fuzzing。即扰乱了fuzzer的代码覆盖率跟踪机制,削弱了fuzzer以任何方式使用反馈机制的能力,从而消除了coverage-guided fuzzer相对于blind fuzzer的优势。
ANTIFUZZ将噪声引入的覆盖率信息的两种技术:
为几乎所有输入产生不同的”有趣”覆盖率
其基本原理是,根据coverage-guide的假设,任何新的覆盖率都意味着fuzzer发现了导致新行为的输入。因此,如果程序始终显示新的覆盖率,则fuzzer无法区分合法的新覆盖率和无效的伪造覆盖率。从而fuzzer会认为每个输入都”有趣”,使得它花费大量时间基于无效输入生成突变。
实现方式:计算程序输入的哈希值,并使用哈希值为索引,选择一个随机的伪造函数子集进行调用。每个伪造函数都从函数指针表递归调用下一个伪造函数。这种方式在程序中引入了大量新的边(edge)
由于即使输入中只有一位的翻转也会导致哈希值完全不同,因此fuzzer生成的几乎所有输入都会显示新行为。
提供看似合理的半硬约束
添加看起来像属于原始应用程序的合法输入处理代码的伪造代码。同时,此代码应包含大量的简单约束以及一些非常困难的约束。这些严格的约束条件可以引起不同解决方案策略的注意,而简单的约束条件则可以使我们向真实的覆盖范围信息中添加噪音。我们通过创建嵌套条件的随机树来创建此伪代码,嵌套的条件树的输入条件范围从简单到复杂。
4.2 Preventing Crash Detection
为了进一步降低coverage-guided fuzzer和blind fuzzer将发现bug的能力,我们引入了两种附加技术来攻击较早确定的假设2。
fuzzer有多种方式检测是否发生了crash,三种最常见的方式是:
- 观察退出状态
- 通过覆写信号处理程序来捕获
- 使用操作系统级别的调试接口(例如ptrace)
ANTIFUZZ尝试通过常见的反调试措施以及自定义信号处理程序来优雅地退出应用程序,以阻止这些方法。
安装自定义信号处理程序之后,ANTIFUZZ有意触发一个自定义信号处理程序可以识别和忽略的段错误(假崩溃)。这样,如果外部实体观察到我们尝试掩盖的崩溃,则它将始终为每个输入观察到崩溃。
值得一提的是,在设计上,伪造崩溃是在与用户输入无关的每个程序执行时触发的。因此,ANTIFUZZ不会基于用户输入引入崩溃。
4.3 Delaying Execution
ANTIFUZZ在不降低受保护程序的性能的前提下攻击假设3。
对策:ANTIFUZZ检查输入是否为格式正确的输入; 当且仅当ANTIFUZZ检测到格式错误的输入时,才会对应用程序进行人为干预。
paper中指出每个输入的减速效果为250ms
为了使这项技术免受自动代码分析(automated code analysis)和补丁工具(patching tools)的攻击,可以向受保护的程序添加计算量大的任务(例如加密,哈希计算甚至是加密货币挖矿),只有给出解决方案才能继续执行。
大多数应用程序期望其输入文件采用某种结构,并能够判断输入是否符合该结构。
因此,ANTIFUZZ不需要依赖任何正式的规范来自动判断结构是否正确。
相反,我们的响应是由程序中现有的错误路径触发的。
对于原型实现,我们不建议自动检测错误路径,而应作为开发人员手动插入它们。
4.4 Overloading Symbolic Execution Engines
本文介绍了两种技术,针对假设4,两种技术均基于以下想法:
将简单的任务用其他的方法改写
两种技术:
- 用强密码哈希值的比较来代替所有输入与常数的比较
- 缺点:如果提供的种子文件包含正确的值,则concolic execution引擎可能仍能够继续求解其他分支。
- 使用分组密码对输入进行加密然后解密
5 Implementatnion Details
该实现由一个Python脚本组成,该脚本会自动生成一个需要包含在目标程序中的C头文件。
本文的实验分析了将ANTIFUZZ应用于LAVA-M(它由四个程序base64,md5sum,uniq和who组成)花费的时间。
5.1 Attacking Coverage-guidance
在实现方面,尽管可以在运行时动态生成用于ANTIFUZZ的代码,但这可能会给依赖静态代码工具的fuzzer造成问题(即,他们可能无法“看到” ANTIFUZZ引入的代码)。
Q:怎么做?为什么无法”看到”
该引擎以300行Python代码实现,生成包含所有随机选择的约束和常量的C文件,并进一步提供了设置配置值(例如,伪基本块的数量)的功能。
随机边的生成是通过洗牌过的数组(输入文件注入的随机性)实现的,该数组由基于数组中的位置(直到一定可配置深度)相互调用的函数组成。
ANTIFUZZ提供了一个名为antifuzz_init()的函数,需要使用输入文件名调用该函数,最好是在应用程序处理该文件之前。
当开发人员要保护其软件免受模糊影响时,需要由开发人员手动进行此更改:开发人员需要添加一行调用此函数的代码。
5.2 Preventing Crash Detection
调用antifuzz_init()时,ANTIFUZZ必须确认崩溃不可被观察到。
如4.2所述,有必要覆写崩溃信号处理程序,并防止ptrace观察到它。
前者,ANTIFUZZ首先检查是否可以覆盖信号:ANTIFUZZ注册了一个自定义信号处理程序,并故意使应用程序崩溃。如果调用了自定义信号处理程序,它将忽略崩溃并恢复执行。
如果应用程序无法在崩溃中存活,则意味着无法覆盖信号,并且就目的而言,
导致的崩溃是理想的副作用。如果应用程序在崩溃中幸存下来,显然,信号覆盖是可能的。
然后,ANTIFUZZ为所有常见的崩溃信号安装自定义信号处理程序,并用超时或正常退出(取决于配置)覆盖这些信号。
后者,对于ptrace,ANTIFUZZ使用一种众所周知的反调试技术:检查是否可以ptrace自己的进程。如果不能ptrace自己的进程,说明有另一个进程正在跟踪它。
5.3 Delay Execution
从实现角度出发,主要思想是允许开发人员在输入格式错误时通知ANTIFUZZ。
开发人员需要在程序中调用antifuzz_onerror()
调用antifuzz_onerror()后,ANTIFUZZ使用第4.3节中提到的机制将执行延迟可配置的时间。
5.4 Overloading Symbolic Execution Engines
针对4.4的两种方法
方法1使用SHA-512实现。开发人员需要用ANTIFUZZ提供的哈希函数替换重要的(基于输入的)比较。
局限:只能进行
==比较,而不能进行大于比较
方法2使用ECB模式AES256加密功能
ANTIFUZZ提供
antifuzz_fread()任何对
fread()的调用都需要替换为其等效的ANTIFUZZ调用。
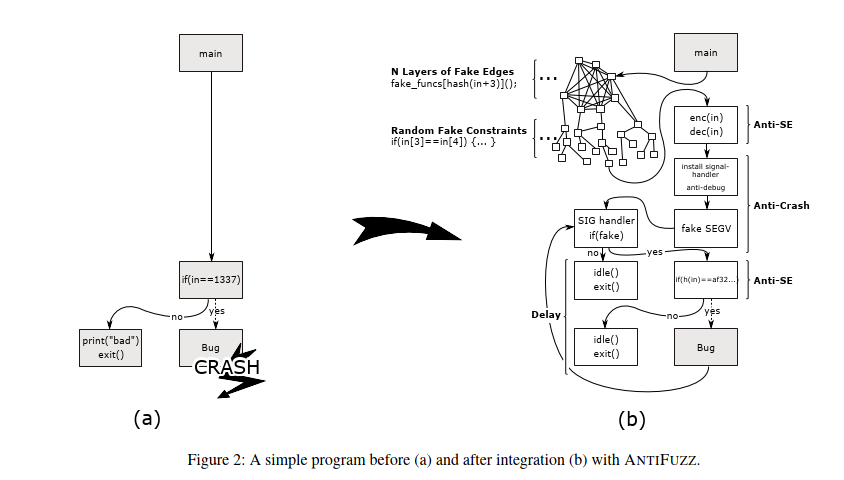
6 Evaluation
评估旨在回答以下五个研究问题(RQ):
- 当前的混淆技术相对于通过模糊进行自动错误发现是否有效?
- 我们设计的技术在破坏目标模糊假设方面是否有效?
- 这些技术是否有效地防止了fuzzer发现错误?
- 这些技术是否有效减少了正在测试的代码量?
- 我们的技术是否引入了显著的性能开销?
简答:
- 使用最新的混淆工具TIGRESS 达不到令人满意的antifuzz效果
- 缓解措施正在按预期进行。
AFL 2.52b, VUZZER, HONGGFUZZ 1.6, DRILLER commit 66a3428, ZZUF 0.15, PEACH 3.1.124, and QSYM commit d4bf407。除此之外还考虑一种基于符号执行的工具:KLEE 1.4.0.0 - 针对RQ3,使用LAVA-M数据集测试了这些fuzzer
- 针对RQ4,对来自binutils的二进制可执行文件进行评估,以显示受保护和不受保护的应用程序在测试覆盖率方面的差异。
- 针对RQ5,使用
SPEC CPU2006基准测试套件来测量ANTIFUZZ引入的开销
由于ANTIFUZZ的可配置性,在所有实验中使用以下配置:
- Attacking Coverage-guidance:生成10,000个带有约束的伪函数,以及10,000个基本块以生成随机边。
- Delaying Execution:在发生崩溃以使应用程序超时的情况下,信号处理程序会导致速度降低(除了输入格式错误导致的速度降低)。睡眠时间设置为750毫秒。
- Preventing Crash Detection:启用了第5.2节中提到的所有技术
- Overloading Symbolic Execution Engines:等效的重要比较已替换为SHA512哈希比较,并且在ECB模式下通过AES-256对输入数据进行了加密和解密。
6.1 Antifuzz versus Software Obfuscation
软件混淆的目标之一是防止依赖传统的手动逆向工程技术的安全研究人员发现错误。在本节中,我们演示了混淆本身无法阻止自动错误查找工具。
没有反馈机制的
blind fuzzer根本不会受到混淆的阻碍,因为它们既不需要代码也不需要任何知识。但是反馈驱动的fuzzer确实需要访问边和基本块来获取可用于指导模糊过程的覆盖率信息。因此,通过通用技术(例如控制流加密或基于虚拟机的模糊处理)模糊控制流可能会影响覆盖率指导的模糊器。
实验为证明混淆技术本身并不能保护应用程序免受fuzzing的影响,使用TIGRESS 2.2混淆了一个dummy应用程序,并让不同的fuzzer找到了正确的崩溃输入。
1 | //dummy Application |
本实验使用AFL,HONGGFUZZ,KLEE和ZZUF来代表所有三个fuzzer类别
请注意,VUZZER被排除在外是因为
- VUZZER基于IDA Pro反汇编程序,它甚至在fuzzing程序开始之前就因混淆而受挫
- Tigress无法编译非64位可执行文件,而VUZZER不能工作在64位二进制文件上
该实验表明,尽管启用了所有混淆技术,所有fuzzer仍可以找到崩溃的输入。
6.2 Finding Crashes in a Simply Dummy Application
使用与先前实验相同的dummy应用程序。
对于此评估,我们一次启用一种antifuzz技术,而不是一次启用所有这些功能。
选择这个相当简单的目标有两个原因:
- 如果模糊器无法找到这个非常浅的错误,则它们很可能也无法找到更复杂的崩溃
- 代码足够简单,可以适应不同的系统和模糊器(例如DRILLER需要CGC 二进制文件)
这一块翻译不下去了,没什么意思,跳过
7 Limitations
人工分析人员可以很容易地删除由ANTIFUZZ添加的保护机制。
但是,根据我们的攻击者模型,我们认为此威胁不在本文的讨论范围之内。
所以本文作者的观点是,使用其他较为成熟的代码混淆等抗分析技术来保护ANTIFUZZ技术
导致延迟的技术不应应用于任何类型的面向公众的服务器软件,因为这会大大削弱服务器抵抗DOS攻击的能力。
作为伪代码添加的功能数量导致固定文件大小增加大约25MB。
此外,值得一提的是,通过使用自修改代码(self-modifying code> ),可以避免文件大小的这种增加。
我们明确决定不使用自修改代码,因为这种技术会使用具有读/写/执行特权的内存页,这使得利用变得更容易;并可能在防病毒产品中引发警报。
此外,当前形式的ANTIFUZZ需要开发人员参与,这从可用性的角度来看并不是最佳的。
另外,值得一提的是,本文使用的基准测试套件重点关注CPU密集型任务,而不是I/O绑定任务。
我们假设使用我们的原型AES实现对每个输入进行加密和解密会显着增加I/O绑定任务的开销。
因此,我们建议使用弱得多,速度更快的加密算法来代替AES,因为我们的目标不是加密安全,而是混淆SMT求解器。
最后,必须考虑的是,总是难以阻止automatic program transformations for obfuscation
8 Related Work
常见代码混淆:
- 注入永远不会执行的垃圾代码
- 自修改代码
针对符号执行:
“Linear obfuscation to combat symbolic execution”
Authors:
Zhi Wang College of Information Technical Science, Nankai University, China
Jiang Ming College of Information Sciences & Technology, Pennsylvania State University
Chunfu Jia College of Information Technical Science, Nankai University, China
Debin Gao School of Information Systems, Singapore Management University, Singapore
其他的antifuzz相关工作
Zhenghao Hu, Yu Hu, and Brendan Dolan-Gavitt. Chaff bugs: Deterring attackers by making software buggier.
核心思想:在目标应用程序中插入大量假错误
本文对其的评价:
优势在于,它可以应对多种不同的攻击情形。
但是,它们依赖于无法利用的错误,否则会降低应用程序的实际安全性。例如,作者声明他们依赖所选编译器的确切堆栈布局行为。对编译器的任何更新都可能使以前的“安全”错误变得可利用。
另外,fuzzer通常会为发现的每个实际错误发现数百至数千次崩溃。添加更多的崩溃不会阻止fuzzer发现真正的错误。发现的大量崩溃可能会引起人们的注意,并且针对漏洞分类的常见分析技术(例如AFL漏洞探索模式)将大大简化清除假漏洞的过程。
Kang等人(Kang Li, Yue Yin, and Guodong Zhu. Afl’s blindspot and how to resist afl fuzzing for arbitrary elf binaries.)在一次演讲中也提出了类似于我们伪造代码插入的想法。但是,他们明确地试图防止AFL-QEMU找到特定的崩溃路径。
最后,Göransson和Edholm的一篇硕士论文介绍了掩盖崩溃并主动检测程序是否被fuzz的想法
与Kang等人的工作类似,他们设计的方法非常适用于他们所考虑的仅两个模糊器的实现:AFL和HONGGFUZZ。另外,为了降低模糊器的执行速度,他们建议人为地降低被测程序的整体性能,而ANTIFUZZ仅在输入格式错误时才降低性能。
Question
- 防得住死代码消除吗
My Discussion
这两篇破东西花了我好几个礼拜。。。本来想写成比较精炼的形式,结果发现水平不够,只能写成文章分析。
但是最后还是可以总结讨论一下。
首先在背景方面存在一个比较大的分歧:代码混淆技术对fuzz的对抗效果。FUZZIFICATION对代码混淆的观点是有效但是开销大,而ANTIFUZZ持有的观点是效果并不好。
所以我也找了很多人,问了这个问题,最后得出的结果是:
- 代码混淆对afl系的fuzzer没有很好的效果,代码混淆主要针对的是程序分析,对于反馈驱动的fuzzer来说并不会影响其反馈的正确性,也就是说代码混淆的应用对这一类fuzzer来说只是把任务升级成”对一个更复杂的程序进行fuzzing”。
- 反之,代码混淆一定程度上会对依赖于程序分析的fuzzer造成影响,目前能想到的就是Vuzzer,这个观点在ANTIFUZZ里也有描述。
然后说说两篇论文。
FUZZIFICATION的实现看起来更自动化一些,不需要过多的开发者干预(LLVM pass+Python Script),而ANTIFUZZ还需要在源代码里手动调用函数。
而ANTIFUZZ在整体的思考方式上比较有趣,首先分析了现代fuzzer依赖的一些假设,然后通过破这些假设来对抗fuzzer的各种加速手段。而且paper里讨论了很多对其他相关工作的评价。
==但是==,ANTIFUZZ,个人观点,有一个致命伤,这也是为什么我不想去翻译它的评估部分。ANTIFUZZ有一个观点:antifuzz的抗分析能力不是他们的关注点,它的抗分析能力应该由其他技术来支持的。所以它的一切评估,尤其是性能开销,应当加上必要的抗分析能力再进行比较才比较合理。
而FUZZIFICATION考虑了自身的抗分析能力,虽然实际效果有待评估,因为它用到的这些技术确实给我的感觉是特征鲜明。
另外一点,两篇文章都承认的一个观点:不计成本,人工分析可以消除antifuzz techniques。
暂时想到这么多,后面想到什么再补。